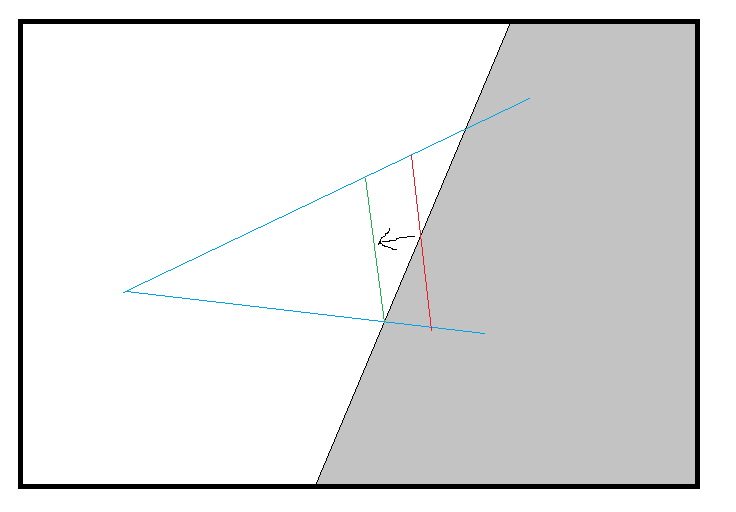
I'd like to come up with a precise formula for shadow map biases. It should be possible to do based on the resolution of the shadow map, area over which it is distributed, and surface normal. The only thing I have a problem with is the non-linear depth value. I don't know how much bias is required to ensure the next discrete value is used.
How can I calculate the discrete values that will be stored in the depth buffer, and then round off to the next lowest?
You can see here, as the surface gets closer to the light source, the depth precision increases and acne starts appearing:

There must be an equation that gives us the precise bias value needed to counteract this.