So I just felt like writing another blogpost, after years of pause. One consistent task in my engine has been optimizing the backend for my visual-scripting language. As anybody who's worked more in Unreal knows, it's blueprints are horribly slow. I've copied the basic interface of blueprints for my needs, as I like what they provide on that end. But I've consistently been working at improving my backends performance. Having something like 10-100x overhead compared to native is simply not acceptable, as I personally use my visual-scripting to code pretty much all games logic (C++ is only used to setup the engine, and it's tools). Some context for the system can be found in my older blog-entries (https://www.gamedev.net/blogs/entry/2261170-visual-scripting-control-structures/)
I'll just post a quick screenshot so that you get an idea of what's being talked about, even if you haven't worked with those kinds of languages before:
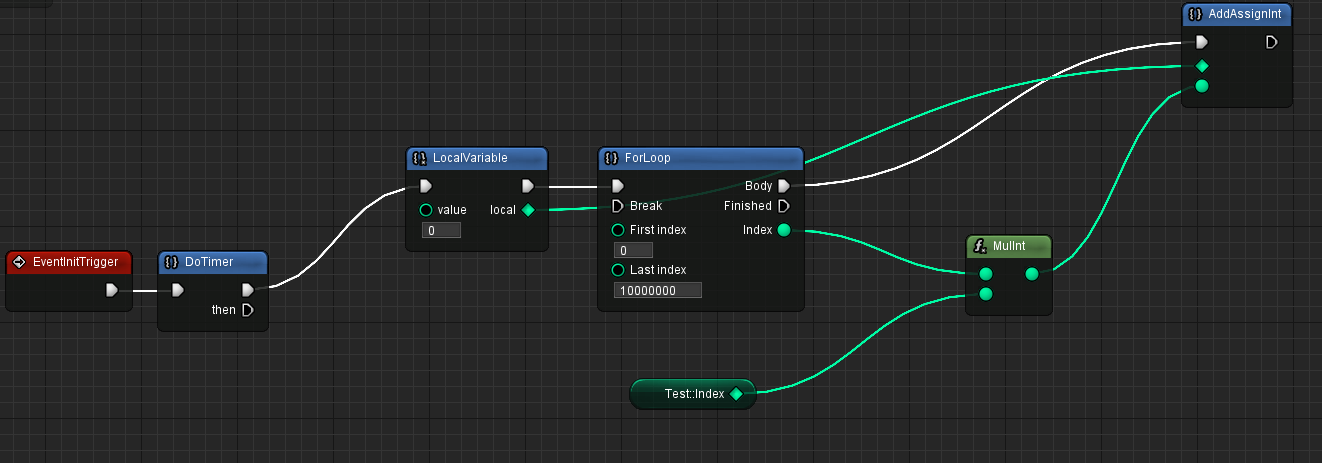
The whole as to “why” I think this is awesome is a whole different topic, and there are better examples where a visual-scripting language can be benefical, than a simple for-loop- but that's not what I'm going to talk about today. Just keep that screenshot in the back of your mind, it will become relevant later.
Getting a somewhat sensible backend
So one question that comes to mind is - what's actually being run here? I'm glad you asked. I started out with a backend where every node was a class with a virtual method - but as you can imagine, that's pretty horrible. Yeah, let's just invoke a virtual function to execute an integer-multiplication, that's real efficient.
I did waste a lot of time trying to optimize this system, but in the end I went with a bytecode-based language.
I generated this language myself, by looking at what Java/C# would be doing. This was a insanely large task, requiring not only the language to be designed, but also a compiler-interface to translate those nodes into the IL that is being generated. Well, the result was a way faster, compiled IL, where code for the above would look like this:
Scene_F5FFFBE7DE8B877A.Test::EventInitTrigger:
LocalVariableSize: 16
Bytecode:
AddSpace 16
LoadDword Scene_F5FFFBE7DE8B877A.<CONTEXT> (%gsp[1]+8)
CallFunctor DoTimer_wrapper, .CFUNCTOR0
InitWord %rbp-12
InitWord %rbp-16
Jump .L0
.L1:
LoadWord %rbp-12
LoadWord %rbp-16
LoadWord Scene_F5FFFBE7DE8B877A.Test::Index (%gsp[1]+80)
MulInt
AddInt
StoreWord %rbp-12
IncrementLocalInt %rbp-16
.L0:
LoadWord %rbp-16
PushIntConst 10000000
LessEqualsWord
JumpIf .L1
LoadDword Scene_F5FFFBE7DE8B877A.<CONTEXT> (%gsp[1]+8)
CallFunctor DoTimer_finalizer, .CFUNCTOR1
Pop 16
Return
CData:
.CFUNCTOR0:
.Array_Local<2> Array<2>
.CFUNCTOR1:
.Array_Local<2> Array<2>Now, this was an extremely huge improvement in terms of execution-speed already. We are talking something like 30-40x faster - that's what I call an optimization!
Though that language is stack-based, similar to java, and uses an interpreter to execute, so we are still far from close to native speeds. And close to native is what I want. I have to mention, that I'm mainly working on a 2D game right now - which, while large in scale and full of content (20-30h story content right now) isn't really that demanding. So why bother? Well, the engine is supposed to be general purpose, and the old backend once was way too slow to do something like 1000 moving objects at the same time, when I tested things in my 3D library. But aside from that, I also have a replay-system, that records frame-perfect inputs, and replays them (engine is deterministic). I use this to validate that my game still works. That means that in practice, I record a session of the entire game, split in sections, and replay all those sections before shipping a build. In case anything breaks, the replay will become desynced at that point (or crash), which not only notifies me of bugs, but also let's me get to the reason for the bug very reliably. But, since I said the game is 20-30h, for this to be practically useful it requires replay to be able to be done in a very sped-up manner. At the moment, I can replay the game with a factor of 1000x, which consists of a fictional framerate of 50000 FPS. Not too bad. The whole test-setup finishes in 90s, which is pretty darn fast. But any way to speed it up would still be a huge gain, as I validate every major change against this framework, to help me spot problems early.
Onto native code
Now, if you've never seen a bytecode-interpreted language, it's basically just some area of memory where you write an opcode (an uint8_t describing the type of operation), and some data (things like offsets, constants, …). You then execute code by reading that data in a while-loop:
while (true)
{
const auto opCode = stream.ReadOpcode();
switch (opCode)
{
case OpCodes::PushWordConst:
{
const auto constant = stream.ReadData<int>();
state.stack.Push<int>(constant);
break;
}
}You've just got to have different opcodes, and you can execute anything. Though as you'd imagine, there is still a large overhead. Even with full optimizations, for everything you do, you not only have to pay the cost of the operation, but the cost of reading the data, switching on the type of instruction, etc… But what else can we do? We can write a JIT.
But that's pretty complicated, and if just coming up with a bytecode-based language takes so long, surely devising a JIT will take even longer, right? Not really. At least not initially.
Don't get me wrong, if you want to compile code on a level of optimization like the C-languages, it does take a lot of effort. But surprisingly, just coming up with a very basic JIT, that removes a lot of the overhead of interpreting, is not that complicated. Think of what the interpreter-loop above does. It will effectively just execute some native instructions, only that it fetches it's instruction, as well as data, from a stream. So how about we just replicate all those CPU-instructions, lay them out in order, inlay all the constant data; but still use the custom stack-structure? And that's exactly what I did. So instead of having aloop that decodes all instructions, we just generate some very naive native code. PushWordConst as above might look something like this:
PushWordConst 1
mov rdx,1
mov rcx,[state] // state.stack stored as first member
call Stack::Push<int>All very basic stuff - and the speedup was also something like 2-3x, if I recall correctly. Of course, there is still a huge ton of overhead, like calling a method for doing the push. I eventually inlined most of the things, but on a base-level, we will always be multiple times slower than native code. For example, storing a “1” on the native stack is as simple as:
push 1But for me, the most optimal thing I could do is:
mov rcx,[rbx] // move Stack&
mov rcx,[rcx] // move Stack.pStack (we have to use a class for Stack to sync accesses)
sub [rcx],4 // add space for int
mov [rcx],1 // store the int at the new stacks top4 instructions, all using memory-operands, just for that one. But I've accepted this for a long time. After all, back then I still had troubles with fully understanding assembly. I used godbolt to study the generated code, as well as the generated encodings of the instructions, but I wasn't fully able to comprehend the whole model. Meaning that any changes I made were very hard to do. The code for generating the instructions was all just very basic and uninformed:
void JitImpl::WriteJumpCallRegisterImpl(Register reg, bool isJump)
{
const auto data = reg.GetData();
AE_ASSERT(data.size == 8);
// jmp [%reg]
const auto offset = isJump ? 0x10 : 0x00;
if (reg.offset)
{
WriteOffsetLine(reg, [&]
{
AddPrefixSingle(data, 4);
WriteSymbol(0xff);
WriteSymbol(0x10 + offset + data.index);
});
}
else // jmp %reg
{
Reserve(3);
// TODO: passing "4" to prevent 64-bit prefix is a hack
AddPrefixSingle(data, 4);
WriteSymbol(0xff);
WriteSymbol(0xd0 + offset + data.index);
}
}As I said, I just inspected the generated bytes, and tried to replicate them.
The road ahead
Yet over the last months, I worked torwards actually getting a deep understanding of assembly, as well as refactor the system, to allow me to make changes more fluently. And I'm on a good way for it. Remember the screenshot from above? Well, I'm proud to say, but as of writing, I was able to match native c++-code in terms of execution-speed, for that specific piece of code. There is still a lot left to do, mostly nativized calling of bind-functions, and so on, but that is already a pretty big win. Being able to match
int local = 0;
for (int i; i < 10000000; i++)
{
local += global * i;
}Is already a good first step. Well, clang is apparently able to convert this whole loop into one instruction, no matter the value of the global - I can't match that. But MSVC isn't able to do that, which is my primary compiler, so I'm ok with just being able to compete with that. It's still a bit funny, because my generated assembly, after transforming the code-generating to use the native stack, is not quite the same as such a loop would produce on a normal compiler. My asm for the loop is as follows:
mov dword ptr [rsp+34h],0
jmp 37h
mov edx,dword ptr [rsp+30h]
mov dword ptr [rsp+58h],edx
mov edx,dword ptr [rsp+34h]
mov dword ptr [rsp+54h],edx
mov edx,dword ptr [rip+1E5Fh]
mov dword ptr [rsp+50h],edx
mov eax,dword ptr [rsp+50h]
imul eax,dword ptr [rsp+54h]
mov dword ptr [rsp+54h],eax
mov eax,dword ptr [rsp+54h]
add eax,dword ptr [rsp+58h]
mov dword ptr [rsp+30h],eax
inc dword ptr [rsp+34h]
mov edx,dword ptr [rsp+34h]
mov dword ptr [rsp+58h],edx
xor eax,eax
cmp dword ptr [rsp+58h],989680h
setle al
mov dword ptr [rsp+58h],eax
mov eax,dword ptr [rsp+58h]
test eax,eax
jne -58hThis is still a rather primitive system, that uses the native RSP-stack, and doesn't fully make use of registers for locals. The actual MSVC-code is only like 5 instructions long, but I've measured multiple times to make sure that the results are similar. It seems that, for that specific example, eigther the bottleneck is such that the actual number of instructions and stack-accesses are not that relevant; or the CPU is able to optimize that assembly to a very similar format internally into its my-ops icache.
Truthfully, I'll probably leave the code-gen at that. Adding support for using registers for locals and such would complicate the code I have to write to compile the instructions extremely. I'll probably just use a peephole-optimizer instead. For example, we could look at those two instructions from above:
mov dword ptr [rsp+50h],edx
mov eax,dword ptr [rsp+50h]So here we store “edx” onto the stack, and immediately read it into “eax”. This is because those two instructions are generated by independant instructions, one that pushes to the stack, the other, that reads from it. But this would not need to be solved by the compiler, necessarily. Once we have to instructions written, we could scan them, and try to detect patterns like the one above. Doing that, we could eliminate the stack-store, and move between registers directly; or potentially just use the same register on both ends.
Finishing things up (for now)
But I'm getting ahead of myself. I just wanted to give the necessary context for what I'm doing right now. Next time (which will only happen if I feel like it, to be fair :D), I'll show you more about the actual framework I built for both disassembling, and generating the assembly in a stable way.
Thanks for reading, if you made it this far.