Keep it simple
I've been trying to implement a small framework to execute parallel algorithms in my engine. I decided to begin with the frustum culling and for the last week I tried to code a thread pool with mutex and load balancing. This was a huge mistake as it's too complex, the load balancing is poor and developing a decent job-stealing scheduler is pretty hard. This idea came with the concept of a global queue, and a local queue per thread. There is a simple pattern you should always follow: KISS (Keep it simple...) A lock-free queue with no mutex is much more efficient. There is no need to implement a job-stealing scheduler, it fits very well thin grained parallel algorithms with no dependencies between threads and it comes out of the box.
Light CPU Jobs
Atomic operation algorithms vs mutex
Posix and Windows mutex are efficient for threads with a lot of dependencies, but they have some drawbacks:
- Force kernel/user space context switches and the delay is quite high, specially on Windows. This makes mutex a bad option for thin parallel algorithms, i.e. realtime applications and a game is a soft realtime application.
- For the same reason mutexes don't scale well, atomic operation algorithms will keep an active waiting on the very same thread improving the performance
On the other hand algorithms based on atomic operations are difficult to debug and depend a lot on the architecture rather than on the OS, making development difficult, but x86 has some memory coherency, therefore if you are targeting this platform atomic operation algorithms will serve well in your engine. There are almost two types of atomic operation algorithms:
- User space blocking algorithms
- User space lock-free algorithms
A lock-free queue for 32 and 64 bit systems
A lock-free queue will be the core of the synchronization in our engine, you will find some implementations out there but these are a little bit messy. Mine has two extra members: done and busy. These members will allow you to sync all the threads without having to add a single mutex.
//-----------------------------------------------------------------------
// momo (2012)
//-----------------------------------------------------------------------
// file: taskqueue.h
// author: Victor Egea Hernando (egea.hernando@gmail.com)
// description: lock-free queue based on
// Simple, Fast, and Practical Non-Blocking and Blocking
// Concurrent Queue Algorithms
// Maged M. Michael Michael L. Scott
// Department of Computer Science
// University of Rochester
//-----------------------------------------------------------------------
#ifndef TASKQUEUE_H #define TASKQUEUE_H
//-----------------------------------------------------------------------
#include #include
//-----------------------------------------------------------------------
// TaskQueue: lock-free queue
//-----------------------------------------------------------------------
template class TaskQueue
{
NO_COPY(TaskQueue)
protected:
//-------------------------------------------------------------------
// structures
//-------------------------------------------------------------------
typedef uint64 Ptr;
//-------------------------------------------------------------------
struct Node { Ptr next; T value; };
//-------------------------------------------------------------------
// Pointer operations
//-------------------------------------------------------------------
static const uint64 PtrMask = 0x003fffffffffffff;
static const uint64 CntMask = 0xffc0000000000000;
//-------------------------------------------------------------------
bool equal(const Ptr& ptr1, const Ptr& ptr2) { return ptr1 == ptr2; }
//-------------------------------------------------------------------
void set(Ptr& ptr, Node* node, uint32 count) { setNode(ptr, node); setCount(ptr, count); }
//-------------------------------------------------------------------
Ptr gen(Node* node, uint32 count) { Ptr ptr; setNode(ptr, node); setCount(ptr, count); return ptr; }
//-------------------------------------------------------------------
void setNode(Ptr& ptr, Node* node)
{
if ((uint64)node & CntMask)
{
dCritical(Format("pointer too long: %1").arg(Format::pointer(node)));
}
ptr = (Ptr)((uint64)ptr & CntMask | ((uint64)node & PtrMask));
}
void setCount(Ptr& ptr, uint32 counter)
{
if (counter >= (1 << 10))
{
counter = counter % (1 << 10);
}
ptr = (Ptr)(((uint64)counter << 54) | ((uint64)ptr & PtrMask));
}
//-------------------------------------------------------------------
Node* pointer(Ptr ptr) { return (Node*)((uint64)ptr & PtrMask); }
uint32 count(Ptr ptr) { return (uint64)ptr >> 54; }
public:
TaskQueue() { Node* node = new Node; set(node -> next, null, 0); set(_head, node, 0); set(_tail, node, 0); _pops = 0; }
//-------------------------------------------------------------------
virtual ~TaskQueue() { delete pointer(_head); }
//-------------------------------------------------------------------
// safe & free-lock operations
//-------------------------------------------------------------------
void push(const T& value)
{
Node* node = new Node;
node -> value = value;
set(node -> next, null, 0);
Ptr tail = null;
//---------------------------------------------------------------
FOREVER
{
tail = _tail;
Ptr next = null;
if (pointer(tail) != null)
{
next = pointer(tail) -> next;
}
if (equal(tail, _tail))
{
if (pointer(next) == null)
{
Ptr ptr = gen(node, count(next) + 1);
Ptr res = atomic::cas64(pointer(tail) -> next, next, ptr);
if (equal(res, next)) { break; }
}
else
{
Ptr ptr = gen(pointer(next), count(tail) + 1);
atomic::cas64(_tail, tail, ptr);
}
}
}
//---------------------------------------------------------------
Ptr ptr = gen(node, count(tail) + 1);
atomic::cas64(_tail, tail, ptr);
}
//-------------------------------------------------------------------
bool pop(T& value)
{
Ptr head = null;
//---------------------------------------------------------------
FOREVER
{
head = _head;
Ptr tail = _tail;
Ptr next = pointer(head) -> next;
if (equal(head, _head))
{
if (pointer(head) == pointer(tail))
{
if (pointer(next) == null) { return false; }
Ptr ptr = gen(pointer(next), count(tail) + 1);
atomic::cas64(_tail, tail, ptr);
}
else
{
value = pointer(next) -> value;
Ptr ptr = gen(pointer(next), count(head) + 1);
if (equal(atomic::cas64(_head, head, ptr), head))
{
atomic::fadd(_pops, 1);
break;
}
}
}
}
//---------------------------------------------------------------
delete pointer(head);
return true;
}
//-------------------------------------------------------------------
void done()
{
atomic::fsub(_pops, 1);
}
//-------------------------------------------------------------------
bool busy() const { return _pops > 0; }
protected:
uint32 _pops;
Ptr _head;
Ptr _tail;
};
//-----------------------------------------------------------------------
#endif // TASKQUEUE_H Adding a CPUJob interface
You could use function pointers but I like to use objects, firstly I have a CPUJob interface: //----------------------------------------------------------------------- // momo (2012) //----------------------------------------------------------------------- // file: cpujobbase.h // author: Victor Egea Hernando (egea.hernando@gmail.com) // description: //----------------------------------------------------------------------- #ifndef CPUJOBBASE_H #define CPUJOBBASE_H //----------------------------------------------------------------------- #include //----------------------------------------------------------------------- // classes //----------------------------------------------------------------------- class CpuJobBase; //----------------------------------------------------------------------- // constants //----------------------------------------------------------------------- static const uint32 MaxJobs = 64; //----------------------------------------------------------------------- // types //----------------------------------------------------------------------- typedef Array JobArray; //----------------------------------------------------------------------- // CpuJobBase //----------------------------------------------------------------------- class CpuJobBase { public: virtual CpuJobBase* clone() const = 0; // clone the cpu-job virtual void exec() = 0; // process as many tasks as you can virtual void collectCpuJobData( // collect cpu-jobs data const JobArray& jobs, // cpu-job array uint32 njobs // number of cpu-jobs ) = 0; }; //----------------------------------------------------------------------- #endif // CPUJOBBASE_H *,> And a frustum culling cpu-job extension for it: //----------------------------------------------------------------------- // CPFCCpuJob: Cross platform frustum culling CPU job //----------------------------------------------------------------------- class CPFCCpuJob : EXTENDS(CpuJobBase) { public: CPFCCpuJob(CameraObject* acamera, const FPlanesTuple& ftuple) { _acamera = acamera; _ftuple = ftuple; } virtual ~CPFCCpuJob() { } //------------------------------------------------------------------- // exec //------------------------------------------------------------------- virtual void exec() { KDNode* node = null; //--------------------------------------------------------------- FOREVER { //----------------------------------------------------------- // 1.- obtain the tasks //----------------------------------------------------------- if (! g_tasks.pop(node)) { if (g_tasks.busy()) { continue; } else { break; } } //----------------------------------------------------------- // 2.- check if the aabb intersects //----------------------------------------------------------- const AABB& aabb = node -> aabb(); Vector3 center = ::val<0>(aabb); Vector3 hasize = ::val<1>(aabb); //----------------------------------------------------------- bool outside = false; for (uint32 i = 0; i < 6; ++i) { Vector4 norfp = ::val<0>(_ftuple).val(i); Vector4 absfp = ::val<1>(_ftuple).val(i); //------------------------------------------------------- float dr = ::val<0>(center) * ::val<0>(norfp) + ::val<1>(center) * ::val<1>(norfp) + ::val<2>(center) * ::val<2>(norfp) + ::val<0>(hasize) * ::val<0>(absfp) + ::val<1>(hasize) * ::val<1>(absfp) + ::val<2>(hasize) * ::val<2>(absfp); //------------------------------------------------------- if (dr < -::val<3>(norfp)) { outside = true; break; // it's outside } } //----------------------------------------------------------- // 3.- add the children to the queue or add the node to the // active camera if it is a leaf //----------------------------------------------------------- if (! outside) { if (! node -> isLeaf()) { const KDNode::Children& children = node -> children(); if (::val<0>(children) != null) { push(::val<0>(children)); } if (::val<1>(children) != null) { push(::val<1>(children)); } } else { _nodes.push_back(node -> leafId()); } } //----------------------------------------------------------- g_tasks.done(); // for every successful pop } } //------------------------------------------------------------------- // collectCpuJobData //------------------------------------------------------------------- virtual void collectCpuJobData(const JobArray& jobs, uint32 njobs) { _acamera -> clearNodes(); for (uint32 i = 0; i < njobs; ++i) { ((CPFCCpuJob*)jobs) -> appendNodes(); } } //------------------------------------------------------------------- // clone //------------------------------------------------------------------- virtual CpuJobBase* clone() const { return new CPFCCpuJob(*this); } //------------------------------------------------------------------- // appendNodes //------------------------------------------------------------------- void appendNodes() const { _acamera -> appendNodes(_nodes); } //------------------------------------------------------------------- // push //------------------------------------------------------------------- static void push(KDNode* node) { g_tasks.push(node); } protected: static TaskQueue g_tasks; //------------------------------------------------------------------- CameraObject* _acamera; FPlanesTuple _ftuple; IndexBuffer _nodes; }; //----------------------------------------------------------------------- TaskQueue CPFCCpuJob::g_tasks; *>*> exec is the shared code block by all the threads and has this structure: Task task = null; FOREVER { // pop just one task if (! g_tasks.pop(task)) { if (g_tasks.busy()) { continue; // wait for more } else { break; // all done } } /* DO SOME WORK: * - Append results to the local job structures * This way there is no need to sync anything outside the cpu-job */ if (something) { // now other cpu-jobs can pick the new task g_tasks.push(new_task); } g_tasks.done(); // for every successful pop } Easy, huh? the tasks should be thin and the thread will take full advantage of available CPUs. Notice that there is no sleep before continue, keep in mind that your engine is a realtime application, let the sync to the queue and forget about it. When all threads are finished they will break the loop and go back to their initial status. When all threads are done, busy is triggered and collectCpuJobData is called for the first job, this will collect the outcome from the cpu-jobs. How do I exec the frustum culling? CPFCCpuJob::push(_root); CpuJobRunner::instance().exec( new CPFCCpuJob(acamera, fpa) );
The CpuJobRunner / Thread Pool
I have my own wrappers to hold cross platform functionality for: thread, event-loop, sync //----------------------------------------------------------------------- // momo (2012) //----------------------------------------------------------------------- // file: cpujobrunner.h // author: Victor Egea Hernando (egea.hernando@gmail.com) // description: //----------------------------------------------------------------------- #include //----------------------------------------------------------------------- class CpuJobRunnerPrivate; //----------------------------------------------------------------------- // CpuJobRunner //----------------------------------------------------------------------- class CpuJobRunner { public: static CpuJobRunner& instance(); //------------------------------------------------------------------- // main interface //------------------------------------------------------------------- void exec( CpuJobBase* cpuJob ); void remove( uint32 coreId ); protected: CpuJobRunner(); virtual ~CpuJobRunner(); //------------------------------------------------------------------- static CpuJobRunner* g_instance; CpuJobRunnerPrivate* d_p; }; //----------------------------------------------------------------------- //----------------------------------------------------------------------- // momo (2012) //----------------------------------------------------------------------- // file: cpujobrunner.cpp // author: Victor Egea Hernando (egea.hernando@gmail.com) // description: //----------------------------------------------------------------------- #include #include //----------------------------------------------------------------------- #include //----------------------------------------------------------------------- #include #include //----------------------------------------------------------------------- #include "cpujobrunner.h" //----------------------------------------------------------------------- // types //----------------------------------------------------------------------- typedef Array ThreadArray; //----------------------------------------------------------------------- // ExecCPUJob //----------------------------------------------------------------------- class ExecCPUJob : EXTENDS(Notifier) { public: ExecCPUJob(CpuJobBase* job) { _job = job; } //------------------------------------------------------------------- // notify //------------------------------------------------------------------- virtual void notify() const { dInfo(Debug::CpuJobInfo, Format("%1 (%2): exec").arg( Thread::current() -> name(), typeid(_job).name())); //--------------------------------------------------------------- _job -> exec(); } protected: CpuJobBase* _job; }; //----------------------------------------------------------------------- // DeleteCPUJob //----------------------------------------------------------------------- class DeleteCPUJob : EXTENDS(Notifier) { public: DeleteCPUJob(uint32 coreId) { _coreId = coreId; } //------------------------------------------------------------------- // notify //------------------------------------------------------------------- virtual void notify() const { dInfo(Debug::CpuJobInfo, Format("%1 (%2): remove").arg( Thread::current() -> name(), Format::integer(_coreId))); //--------------------------------------------------------------- CpuJobRunner::instance().remove(_coreId); } protected: uint32 _coreId; }; //----------------------------------------------------------------------- // CpuJobRunnerPrivate //----------------------------------------------------------------------- class CpuJobRunnerPrivate { public: CpuJobRunnerPrivate(); virtual ~CpuJobRunnerPrivate(); //------------------------------------------------------------------- // main interface //------------------------------------------------------------------- void exec( CpuJobBase* cpuJob ); void remove( uint32 coreId ); protected: uint32 _ncores, _ancores; ThreadArray _threads; JobArray _jobs; }; //----------------------------------------------------------------------- CpuJobRunnerPrivate::CpuJobRunnerPrivate() { if (Thread::current() != Thread::main()) { dCritical("WindowPane::init should be run in the main thread"); } //------------------------------------------------------------------- _ncores = std::min(Thread::numCores(), MaxJobs); //------------------------------------------------------------------- for (uint32 i = 1; i < _ncores; ++i) { Format thname = Format("core-%1").arg(Format::integer(i)); _threads = new Thread(thname); _threads.at(i) -> setCore(i); _threads.at(i) -> start(); } } //----------------------------------------------------------------------- CpuJobRunnerPrivate::~CpuJobRunnerPrivate() { } //----------------------------------------------------------------------- // exec //----------------------------------------------------------------------- void CpuJobRunnerPrivate::exec(CpuJobBase* cpuJob) { if (Thread::current() != Thread::main()) { dCritical("WindowPane::init should be run in the main thread"); } //------------------------------------------------------------------- _ancores = _ncores; if (Debug::instance().isFlagActive(Debug::ForceSeqCode)) { _ancores = 1; } //------------------------------------------------------------------- // 1.- create and run the jobs //------------------------------------------------------------------- _jobs[0] = cpuJob; //------------------------------------------------------------------- for (uint32 i = 1; i < _ancores; ++i) { //--------------------------------------------------------------- // 1.1.- create a new cpu-job and reset the status //--------------------------------------------------------------- bool success = false; //--------------------------------------------------------------- for (uint32 j = 0; i < 4; ++j) { if (_jobs.at(i) == null) { _jobs = cpuJob -> clone(); success = true; break; } else { if (j < 3) { os::msleep(2); } } } //--------------------------------------------------------------- if (! success) { dCritical(Format("job %1: still active").arg(Format::integer(i))); } //--------------------------------------------------------------- // 1.2.- run the job //--------------------------------------------------------------- EventLoop::notify( "ExecCPUJob", _threads.at(i), new ExecCPUJob(_jobs.at(i)) ); } //------------------------------------------------------------------- dInfo(Debug::CpuJobInfo, Format("%1: exec").arg(typeid(cpuJob).name())); //------------------------------------------------------------------- cpuJob -> exec(); //------------------------------------------------------------------- // 4.- collect the cpu-job data //------------------------------------------------------------------- cpuJob -> collectCpuJobData(_jobs, _ancores); //------------------------------------------------------------------- // 5.- delete the cpu-jobs //------------------------------------------------------------------- for (uint32 i = 1; i < _ancores; ++i) { EventLoop::notify( "DeleteCPUJob", _threads.at(i), new DeleteCPUJob(i) ); } delete cpuJob; } //----------------------------------------------------------------------- // remove //----------------------------------------------------------------------- void CpuJobRunnerPrivate::remove(uint32 coreId) { if (_jobs.at(coreId) != null) { delete _jobs.at(coreId); _jobs[coreId] = null; } else { dWarning(Format("the job %1 was already deleted").arg( Format::integer(coreId))); } } //----------------------------------------------------------------------- // CpuJobRunner //----------------------------------------------------------------------- CpuJobRunner* CpuJobRunner::g_instance = null; //----------------------------------------------------------------------- CpuJobRunner::CpuJobRunner() { d_p = new CpuJobRunnerPrivate(); } //----------------------------------------------------------------------- CpuJobRunner::~CpuJobRunner() { delete d_p; } //----------------------------------------------------------------------- // instance //----------------------------------------------------------------------- CpuJobRunner& CpuJobRunner::instance() { if (g_instance == null) { g_instance = new CpuJobRunner(); } return *g_instance; } //----------------------------------------------------------------------- // exec //----------------------------------------------------------------------- void CpuJobRunner::exec(CpuJobBase* cpuJob) { d_p -> exec(cpuJob); } //----------------------------------------------------------------------- // remove //----------------------------------------------------------------------- void CpuJobRunner::remove(uint32 coreId) { d_p -> remove(coreId); } //----------------------------------------------------------------------- *,>
And a clean SSE4 cpu-job version
//----------------------------------------------------------------------- // exec //----------------------------------------------------------------------- void SimdFCCpuJob::exec() { Array nodes; Array aabbs; uint32 nnodes = 0; //------------------------------------------------------------------- // prepare the frustum culling data //------------------------------------------------------------------- Array<__m128, 6> xmm_norfp_x, xmm_absfp_x; Array<__m128, 6> xmm_norfp_y, xmm_absfp_y; Array<__m128, 6> xmm_norfp_z, xmm_absfp_z; Array<__m128, 6> xmm_norfp_w; //------------------------------------------------------------------- for (uint32 i = 0; i < 6; ++i) { Vector4 norfp = ::val<0>(_ftuple).val(i); Vector4 absfp = ::val<1>(_ftuple).val(i); //--------------------------------------------------------------- xmm_norfp_x = _mm_load_ps1(&::get<0>(norfp)); xmm_absfp_x = _mm_load_ps1(&::get<0>(absfp)); xmm_norfp_y = _mm_load_ps1(&::get<1>(norfp)); xmm_absfp_y = _mm_load_ps1(&::get<1>(absfp)); xmm_norfp_z = _mm_load_ps1(&::get<2>(norfp)); xmm_absfp_z = _mm_load_ps1(&::get<2>(absfp)); xmm_norfp_w = _mm_load_ps1(&::get<3>(norfp)); } //------------------------------------------------------------------- FOREVER { //--------------------------------------------------------------- // 1.- obtain the tasks (max 4 kdnodes) //--------------------------------------------------------------- bool tryagain = false; //--------------------------------------------------------------- for (nnodes = 0; nnodes < 4; ++nnodes) { if (! g_tasks.pop(nodes.get(nnodes))) { if (nnodes == 0) { if (g_tasks.busy()) { tryagain = true; break; } else { return; } } else { break; } } } //--------------------------------------------------------------- if (tryagain) { continue; } //--------------------------------------------------------------- // 2.- get the AABBs //--------------------------------------------------------------- for (uint32 i = 0; i < nnodes; ++i) { aabbs.get(i) = nodes.at(i) -> aabb(); } //--------------------------------------------------------------- // 2.1.- load the 4 center/extents pairs for the 4 AABBs //--------------------------------------------------------------- __m128 xmm_c0 = _mm_load_ps(::get<0>(::get<0>(aabbs)).array()); __m128 xmm_c1 = _mm_load_ps(::get<0>(::get<1>(aabbs)).array()); __m128 xmm_c2 = _mm_load_ps(::get<0>(::get<2>(aabbs)).array()); __m128 xmm_c3 = _mm_load_ps(::get<0>(::get<3>(aabbs)).array()); //--------------------------------------------------------------- __m128 xmm_e0 = _mm_load_ps(::get<1>(::get<0>(aabbs)).array()); __m128 xmm_e1 = _mm_load_ps(::get<1>(::get<1>(aabbs)).array()); __m128 xmm_e2 = _mm_load_ps(::get<1>(::get<2>(aabbs)).array()); __m128 xmm_e3 = _mm_load_ps(::get<1>(::get<3>(aabbs)).array()); //--------------------------------------------------------------- // 2.2.1.- shuffle the data in order (xy) //--------------------------------------------------------------- __m128 xmm_c0xyc1xy = _mm_shuffle_ps( xmm_c0, xmm_c1, _MM_SHUFFLE(0, 1, 0, 1) ); __m128 xmm_c2xyc3xy = _mm_shuffle_ps( xmm_c2, xmm_c3, _MM_SHUFFLE(0, 1, 0, 1) ); __m128 xmm_c0123x = _mm_shuffle_ps( xmm_c0xyc1xy, xmm_c2xyc3xy, _MM_SHUFFLE(3, 1, 3, 1) ); __m128 xmm_c0123y = _mm_shuffle_ps( xmm_c0xyc1xy, xmm_c2xyc3xy, _MM_SHUFFLE(2, 0, 2, 0) ); //--------------------------------------------------------------- __m128 xmm_e0xye1xy = _mm_shuffle_ps( xmm_e0, xmm_e1, _MM_SHUFFLE(0, 1, 0, 1) ); __m128 xmm_e2xye3xy = _mm_shuffle_ps( xmm_e2, xmm_e3, _MM_SHUFFLE(0, 1, 0, 1) ); __m128 xmm_e0123x = _mm_shuffle_ps( xmm_e0xye1xy, xmm_e2xye3xy, _MM_SHUFFLE(3, 1, 3, 1) ); __m128 xmm_e0123y = _mm_shuffle_ps( xmm_e0xye1xy, xmm_e2xye3xy, _MM_SHUFFLE(2, 0, 2, 0) ); //--------------------------------------------------------------- // 2.2.2.- shuffle the data in order (z) //--------------------------------------------------------------- __m128 xmm_c01z = _mm_shuffle_ps( xmm_c0, xmm_c1, _MM_SHUFFLE(2, 0, 2, 0) ); __m128 xmm_c23z = _mm_shuffle_ps( xmm_c2, xmm_c3, _MM_SHUFFLE(2, 0, 2, 0) ); __m128 xmm_c0123z = _mm_shuffle_ps( xmm_c01z, xmm_c23z, _MM_SHUFFLE(3, 1, 3, 1) ); //--------------------------------------------------------------- __m128 xmm_e01z = _mm_shuffle_ps( xmm_e0, xmm_e1, _MM_SHUFFLE(2, 0, 2, 0) ); __m128 xmm_e23z = _mm_shuffle_ps( xmm_e2, xmm_e3, _MM_SHUFFLE(2, 0, 2, 0) ); __m128 xmm_e0123z = _mm_shuffle_ps( xmm_e01z, xmm_e23z, _MM_SHUFFLE(3, 1, 3, 1) ); //--------------------------------------------------------------- // 3.- check if the aabb intersects //--------------------------------------------------------------- __m128 xmm_tmp, xmm_dpr; //--------------------------------------------------------------- uint32 mask = 0; //--------------------------------------------------------------- for (uint32 i = 0; i < 6; ++i) { xmm_dpr = _mm_mul_ps(xmm_c0123x, xmm_norfp_x); xmm_tmp = _mm_mul_ps(xmm_c0123y, xmm_norfp_y); xmm_dpr = _mm_add_ps(xmm_dpr, xmm_tmp); xmm_tmp = _mm_mul_ps(xmm_c0123z, xmm_norfp_z); xmm_dpr = _mm_add_ps(xmm_dpr, xmm_tmp); xmm_tmp = _mm_mul_ps(xmm_e0123x, xmm_absfp_x); xmm_dpr = _mm_add_ps(xmm_dpr, xmm_tmp); xmm_tmp = _mm_mul_ps(xmm_e0123y, xmm_absfp_y); xmm_dpr = _mm_add_ps(xmm_dpr, xmm_tmp); xmm_tmp = _mm_mul_ps(xmm_e0123z, xmm_absfp_z); xmm_dpr = _mm_add_ps(xmm_dpr, xmm_tmp); //----------------------------------------------------------- mask |= _mm_movemask_ps( _mm_add_ps(xmm_dpr, xmm_norfp_w) ); //----------------------------------------------------------- if (mask & 0xf == 0xf) { break; // all are outside } } //--------------------------------------------------------------- // 3.- add the children to the queue or add the node to the // active camera if it is a leaf //--------------------------------------------------------------- for (uint32 i = 0; i < nnodes; ++i) { if (! ((mask & (1 << i)) >> i)) { if (! nodes.at(i) -> isLeaf()) { const KDNode::Children& children = nodes.at(i) -> children(); if (::val<0>(children) != null) { push(::val<0>(children)); } if (::val<1>(children) != null) { push(::val<1>(children)); } } else { _nodes.push_back(nodes.at(i) -> leafId()); } } g_tasks.done(); // for every successful pop } } } ,>*,>
Performance
Tested loading a scene with a very dense kd-tree (time in ms).
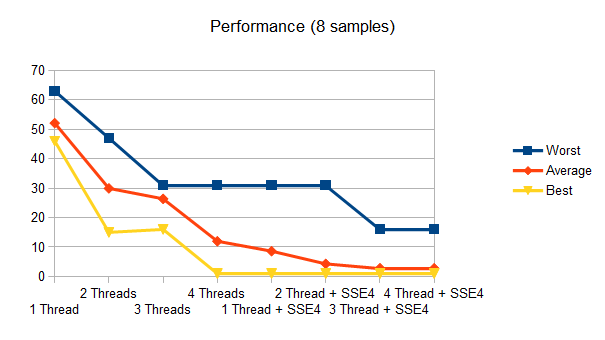
Conclusion
Four threads are not able to beat SSE4, even with a fine grained approach. SSE4 is much more stable than using parallel programming, nonetheless more cores can provide an extra boost to the frustum culling, and with some parameter adjustments the user can even decide what kind of optimization is going to be used. Designing a good framework for parallel algorithms isn't that difficult using lock-free queues, and you can integrate it into your own engine without too much trouble. Bibliography: ? http://www.valvesoftware.com/publications/2007/GDC2007_SourceMulticore.pdf





With some more work though, I think that this could be turned into an interesting case study. Thread pools are not the way to approach this distribution problem, too much overhead is spent in the queue even if it is lockless. Amdahl's law will destroy any possible gains.
Anyway, Victor, if you would like to discuss how to fix this up, let me know in a private message. I think you have a solid start but need to get more details to explain the conclusions properly.