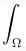JoeJ said:
But tbh, i trust the expertise of blender devs more than my ability to read the rendering eq. ; )
The problem is - you can trust them, and they likely implement their variant of rendering equation correctly, but does it match whatever you're trying to do on base level?
Let me demonstrate - these 3 rendering equations are all valid:
Where, everything is as in previous, but additionally:
- t represents specific time point
- lambda represents wavelength
All of these are correct rendering equations, but the middle one allows for temporal based effects (motion blur, etc.) and the bottom one additionally allows for spectral rendering (light dispersion for example) as it operates on wavelengths.
Does solution of the first equation for some scene become equal to the last? Only under very specific circumstances - and that's one of the major problems. Of course - f_r will often also differ, and so on (do you use only Blinn-Phong BRDF on everything, or do you even use different per different object … or even worse, different B*DF functions - some using subsurface scattering, some not … participating media also breaks this massively, etc.).
This being said - you did eliminate most of the other properties and removed different f_r (by forcing diffuse-only) - thus likely making the rendering equation the same.
In technical/academic paper it is necessary that you additionally prove (to what I mentioned that needs to be proven) that conditions are the same - otherwise the whole comparison loses sense. This becomes mathematically even more challenging than proving that your naive integrator actually works correctly for given rendering equation.
EDIT: Well… not necessarily you need to prove, but not doing so may end up in various questions. Of course doing a mistake there can make your whole work irrelevant.